next 13 그냥 쓰지맙시다. | Strapi 나만의 블로그 만들기(4)

😵💫 최대한 가볍게
사실 화면을 구현할 것도 없었다. 정말 간단한 블로그라 데이터를 불러오고 카드형식으로 뿌리고 클릭했을 때 detail page만 나오면 되는 초간단 사이드프로젝트였다. 그 자만이 나를 지옥으로 이끌었으니,,,
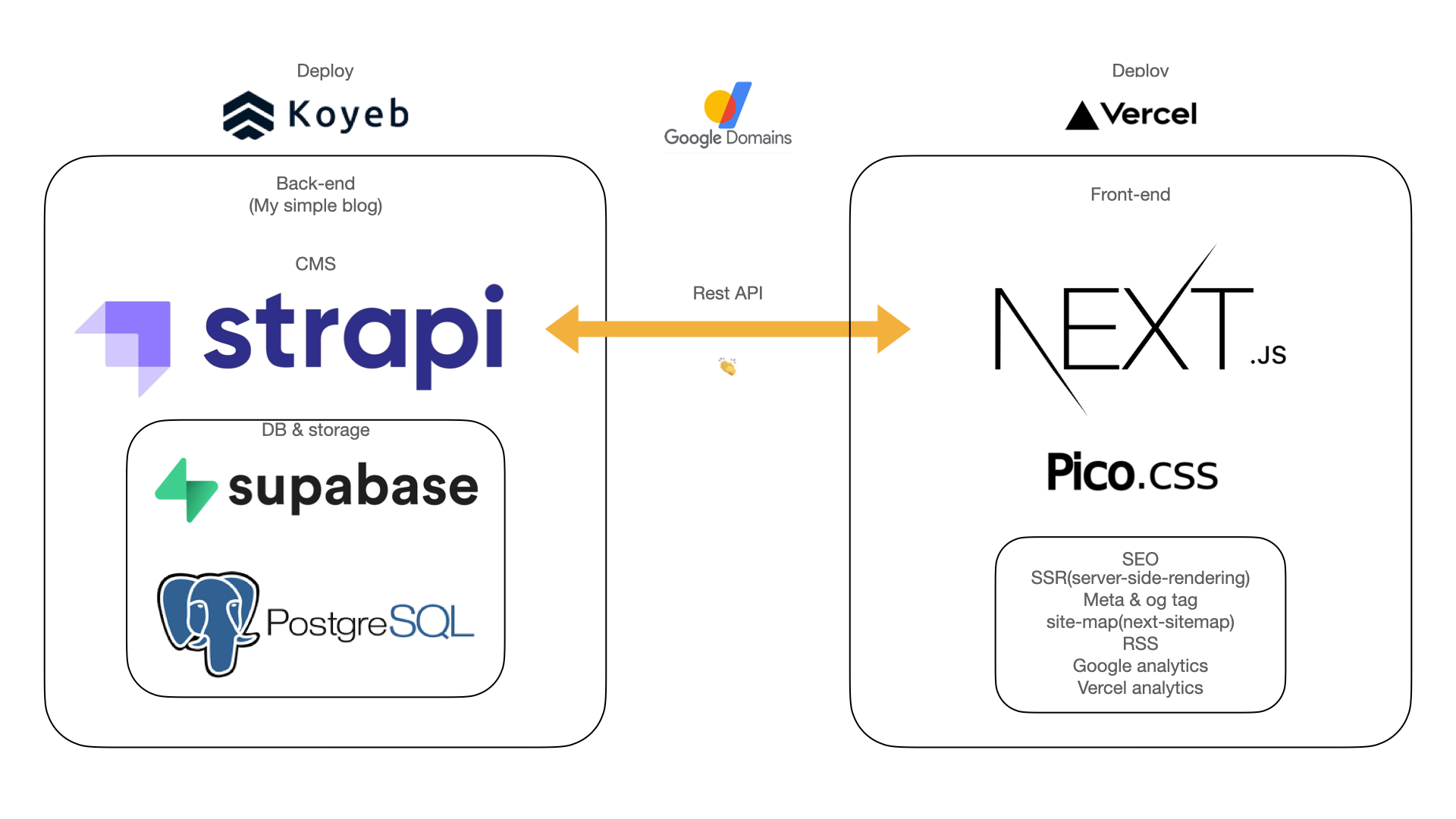
nextjs + javascript + picoCss
(개발보다 문서작업이 더오래걸려서 ts 가져다 버림)
next13으로 바뀌면서 기본 문법들이 많이 바뀌었다.
그래서 기존 블로그 보고 참고하면 다 작살날 수 있으니, 반드시 공식문서를 참고하자.
구상
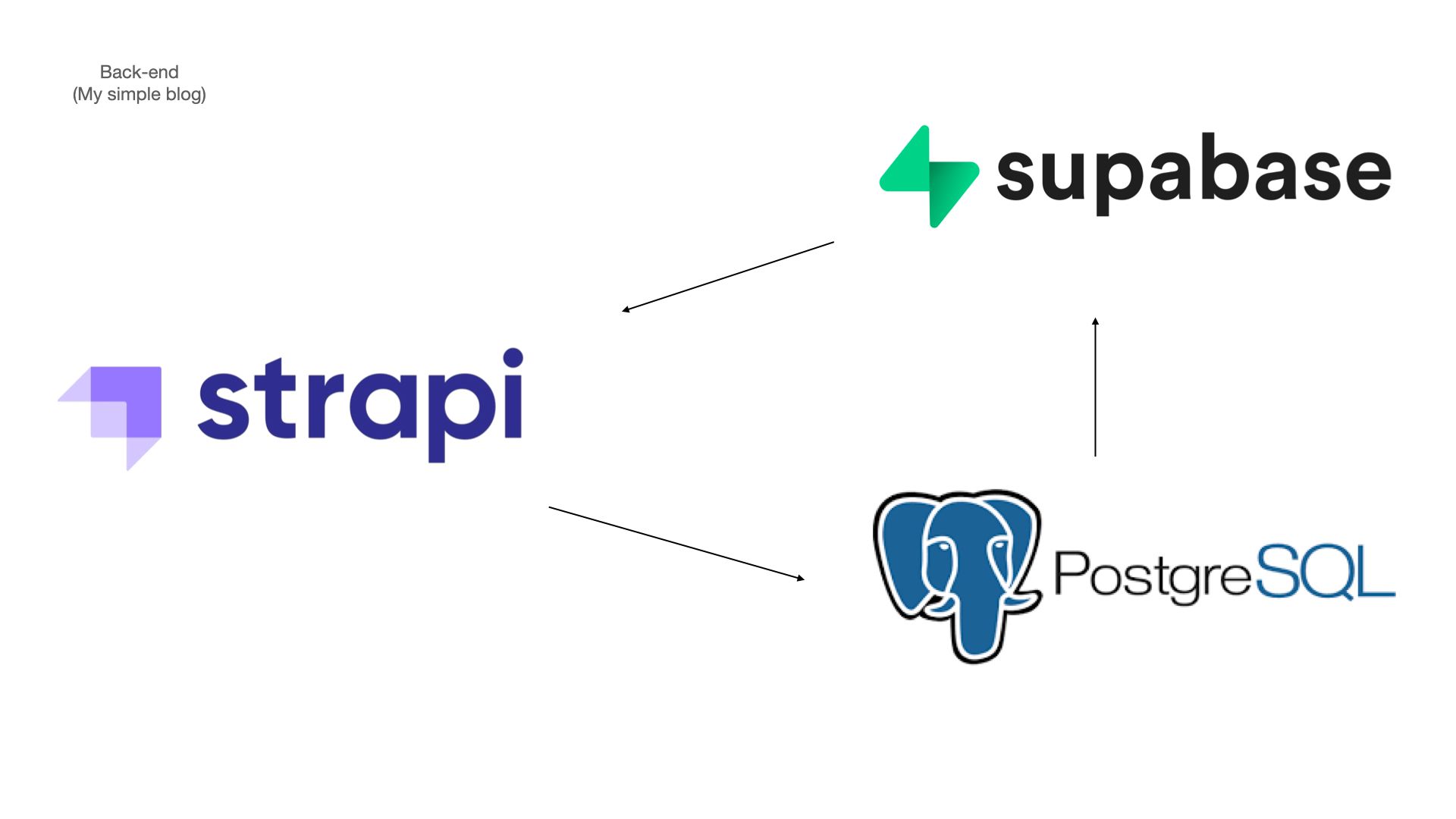
잘 구현된 백엔드 서버 데이터를 rest-ful 하게 불러와서 사용하면 된다.
ssr이 대세가 된 이유는 검색엔진최적화가 잘 되기 때문이다 (SEO) 이는 서버사이드에서 데이터를 다불러다가 주기 때문에 초기렌더링은 약간 느리지만 브라우저에 갔을땐 이미 데이터가 글자나 숫자 등 봇이 읽을 수 있는 코드로 들어가있기때문에 크롤링이 잘 될 수 있다.
그래서 next.js는 기본적으로 ssr을 기본으로 한다.
클라이언트에서는 어떤 주소로 어떤데이터를 불렀는지 볼수도 없어서 보안차원에서도 좋다.
strapi가 제공하는 가이드에 따라 데이터를 불러와보자.
RESTAPI
Example request
GET `http://localhost:1337/api/restaurants`
GET[메서드]
[도메인]/api/[테이블명]쉽다.
나는 코옙에 배포한 주소에 /api / posts 주소로 요청하면 된다.
(strapi 는 컬렉션 명을 테이블에서 복수형으로 바꾼다. 그래서 post 여도 posts 이는 db에서 테이블을 확인해보기 바란다.)
이렇게 api call을 하면 관련된 엔티티 테이블은 불러올 수 없다. 그래서 population를 옵션으로 넣어줘야한다.
//Example request
GET http://localhost:1337/api/restaurants?populate=*?sort=id:desc
//나는 최신순으로 불러오기 위해 id값을 기준으로 desc 정렬도 부탁했다.
아무튼 해당 값을 초기 화면에서 서버사이드로 불러와주고, (SSR을 위한 필수) next13에선 데이터 패칭 방법이 약간 바뀌었다.
기존 자료 블로그에서 찾아 넣으면 낭패본다. 닥치고 공식문서를 보는 습관을 갖자
async function getData() {
const res = await fetchAPI("/posts", {
populate: ["main_cover"],
sort: ["id:desc"],
});
return { props: { posts: res } };
}
export default async function Page() {
const {
props: { posts },
} = await getData();
return (
<div>
{posts.map((card, i) => (
<div key={card.publishedAt}>
<Cards card={card} />
</div>
))}
</div>
);
}암튼 이렇게 불러와서 Card 컴포넌트에 뿌려주고 Card 컴포넌트의 사진이나 더보기를 누르면 <Link> 로 해당 id 값의 dynamic route로 이동해 다시 해당 id값을 feching 해주는 구조이다. 너무나도 쉽고, 직관적인 방식으로 구현한거라 내용은 생략하겠다.
meta tag & og tag (next13)
Metadata Object and generateMetadata Options 공식문서 댓글참고
라이브러리를 깔고 뭐 이상한 짓하지말아라 그냥 공식문서에서 하란대로만 하자. 기존에 layout.js 에 static한 메타나 og 태그를 넣는다.
//layout.js
// static metadata
export const metadata = {
title: "나의블로그",
...
}이건 좋은데, 이제 [id] 값 별로 바뀌는 애들에 대한 메타데이터를 또 넣어야한다.
쉽게 아이디어를 생각해보면 param로 id 값을 받아와서 이 정보를 가지고 데이터와 그 값을 토대로 메타데이터를 담아준다. 이 행위는 server에서 해주는 것이기때문에 브라우저에 렌더링 되기 전에 일어난다.
//post/[id]/page.js
// dynamic metadata
export const generateMetadata = async ({ params }) => {
const {
props: { post },
} = await getData(params.id);
return {
title: `${post?.attributes.title} | 나의블로그`,
...
}next image 활용
next가 제공하는 image를 활용하면 여러가지 이점이있다. 귀찮게 설정해줘야하는 최적화 작업을 다해주기 때문에 안쓰면 바보다. 이 또한 개똥같은 블로그들이 정리해둔 쓰레기같은 문서가 있기때문에 꼭 공식문서에서 어트리븃을 체크해보길 바란다. cover=fill 이딴건 이미 쓰지않는다.
"use client";
import Image from "next/image";
export default function NextImage({ image }) {
const { alternativeText, width, height, url } = image.data[0].attributes;
return (
<Image
fill
style={{ objectFit: "cover" }}
src={url}
alt={alternativeText || ""}
placeholder="blur"
/>
);
}
site-map 구축
뭐 사이트가 최적화되기위해선 사이트맵을 제출해야된다는데 진짜 귀찮다.
무슨 구현보다 잡일이 더 많은 것 같다. 하지만 구글이 하라면 해야된다.
뭐 네이버나 구글콘솔에 등록해야된다나 모라나
next-sitemap 활용했다. 이또한 욕나오는 블로그들을 참고하다가 해당 라이브러리 공식문서를 보고 하니 잘 되었다. 이상한거 보고하면 오히려 엄청꼬이니까 그냥 공식문서봐라
- next-sitemap.config.js 세팅
- server-sitemap.xml 세팅
- 패키지 제이슨에 postbuild 스크립트 추가
// 최상단/next-sitemap.config.js
/** @type {import('next-sitemap').IConfig} */
module.exports = {
siteUrl: process.env.NEXT_PUBLIC_BLOG_URL, // .게시하는 site의 url
generateRobotsTxt: true, // robots.txt generate 여부 (자동생성 여부)
sitemapSize: 7000, // sitemap별 최대 크기 (최대 크기가 넘어갈 경우 복수개의 sitemap으로 분리됨)
changefreq: "daily", // 페이지 주소 변경 빈도 (검색엔진에 제공됨) - always, daily, hourly, monthly, never, weekly, yearly 중 택 1
priority: 1, // 페이지 주소 우선순위 (검색엔진에 제공됨, 우선순위가 높은 순서대로 크롤링함)
exclude: ["/server-sitemap.xml"], // <= exclude here
robotsTxtOptions: {
// 정책 설정
policies: [
{
userAgent: "*", // 모든 agent 허용
allow: "/", // 모든 페이지 주소 크롤링 허용
// disallow: [
// "/exclude", // exclude로 시작하는 페이지 주소 크롤링 금지
// ],
},
// 추가 정책이 필요할 경우 배열 요소로 추가 작성
],
additionalSitemaps: [
`${process.env.NEXT_PUBLIC_BLOG_URL}/server-sitemap.xml`,
],
}, // robots.txt 옵션 설정
};
이제 app / server-sitemap.xml(폴더임) / route.js를 만들자.
import { getServerSideSitemap } from "next-sitemap";
import axios from "axios";
export async function GET(request) {
// Method to source urls from cms
// const urls = await fetch('https//example.com/api')
const getApiData = await axios(
`${process.env.NEXT_PUBLIC_STRAPI_API_URL}/api/posts`
);
const sitemapFields = getApiData?.data.data.map((item) => {
return {
loc: `${process.env.NEXT_PUBLIC_BLOG_URL}/post/${item.id}`, // 페이지 경로
lastmod: new Date().toISOString(), // 최근변경일자
changefreq: "daily", // 페이지 주소 변경 빈도 (검색엔진에 제공됨) - always, daily, hourly, monthly, never, weekly, yearly 중 택 1
priority: 0.9, // 페이지 주소 우선순위 (검색엔진에 제공됨, 우선순위가 높은 순서대로 크롤링함)
};
});
return getServerSideSitemap(sitemapFields);이게 next 13 sitemap 기준 돌아가는 코드이다. 이걸 참고해서 돌아가지 않길빈다. 나는 2일걸렸는데 그냥 다지우고 하니까 됐다. 도메인/site-amp.xml 접속
추가 입력
google naver에 내 사이트라는걸 인증하는 코드를 때려 박아야된다. 이 또한 next13에서는 내용이 바뀌어서 힘들었다. 메타데이터에 잘끼워넣으면 되고, 모르면 댓글 달아주세요.
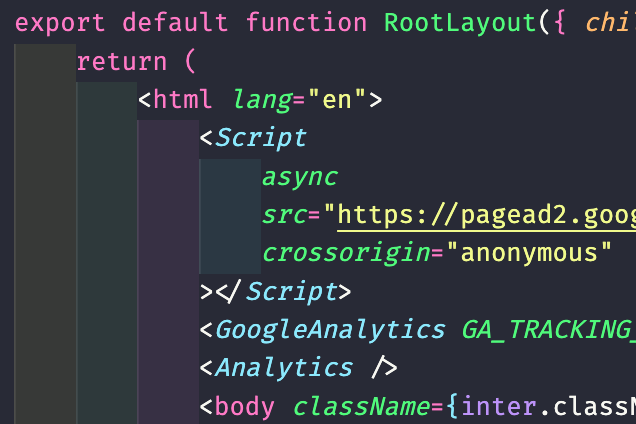
스크립트 이런거 넣어야 할 일이 많은데 _app이나 _도큐먼트가 없어져서 어따 넣어야 하나 고민일텐데 Layout.jsx에 넣으면 된다. 아래처럼
구글애드 구글분석기 버셀분석기 다 때려넣기
vercel deploy
이정도 했으면 됐다. 배포하자해서 vercel에 레포 공유하고 배포를 했다. 뭐 안 될 일이 없어서 잘 배포되었다.
근데 치명적인 문제가 발견되었다.
- 로컬에선 문제없이 잘 됨!
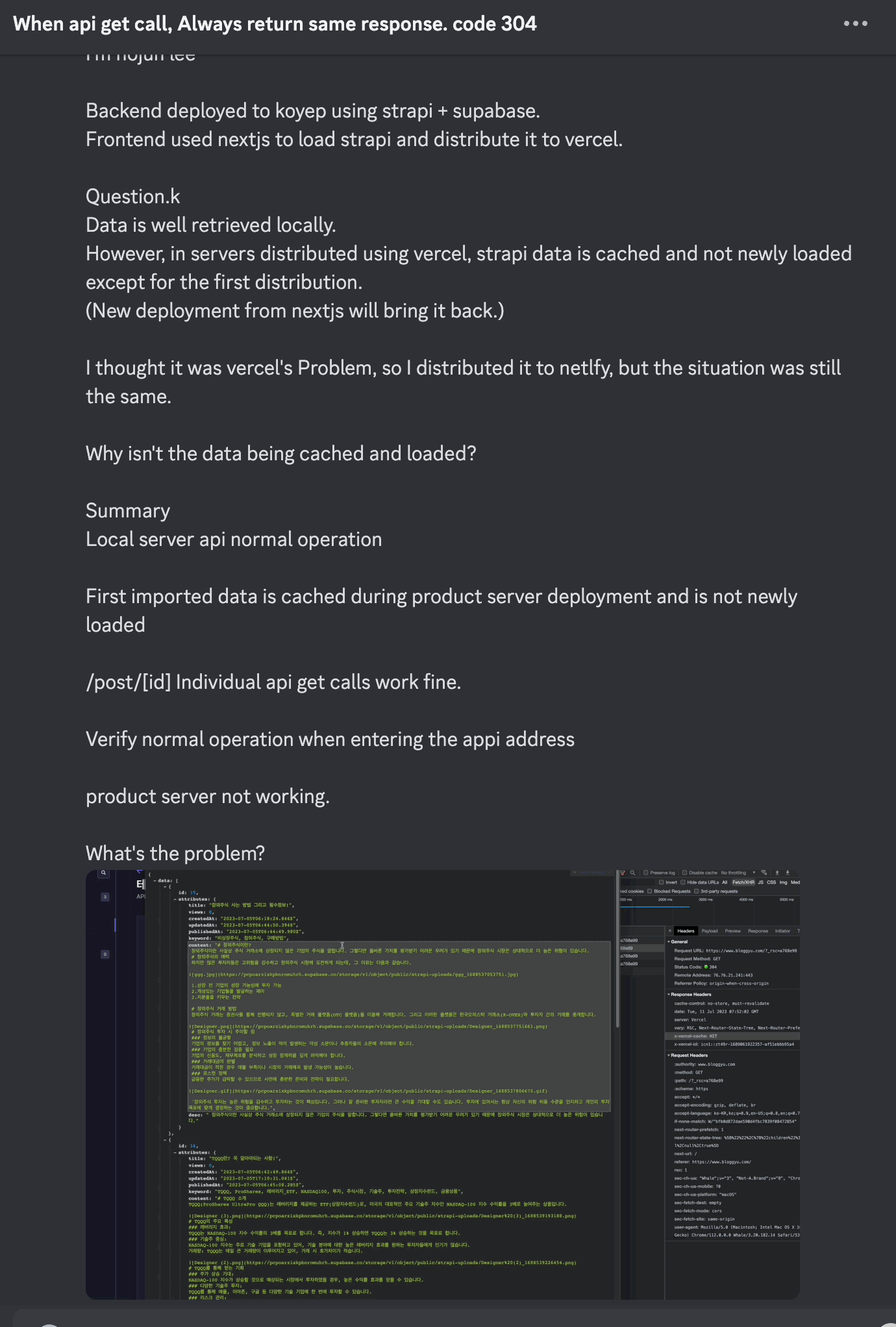
처음에 로컬에서 푸쉬해서 리디플로이 될 때만 데이터 페칭이 정상적으로 됨. strapi를 통해 글을 새로쓰거나 발행을 취소하거나 했을 때 데이터가 계속 불러와지지 않았다. 쉽게말해 데이터가 캐싱되어서 최신화가 되지 않았다. 문제가 뭘까 고민해봤다.
- Vercel 즉 deploy의 문제이다. 아니 next 도 vercel 놈들이 만든건데 둘이 잘 안붙는다는게 말이 안됐다.
- strapi 즉 api를 보내주는 cms의 문제다. 합리적으로 얘네 문제일거라 생각했는데 Postman으로 요청해보면 api가 잘 들어오는 것을 볼 수 있다.
vercel의 문제인가?
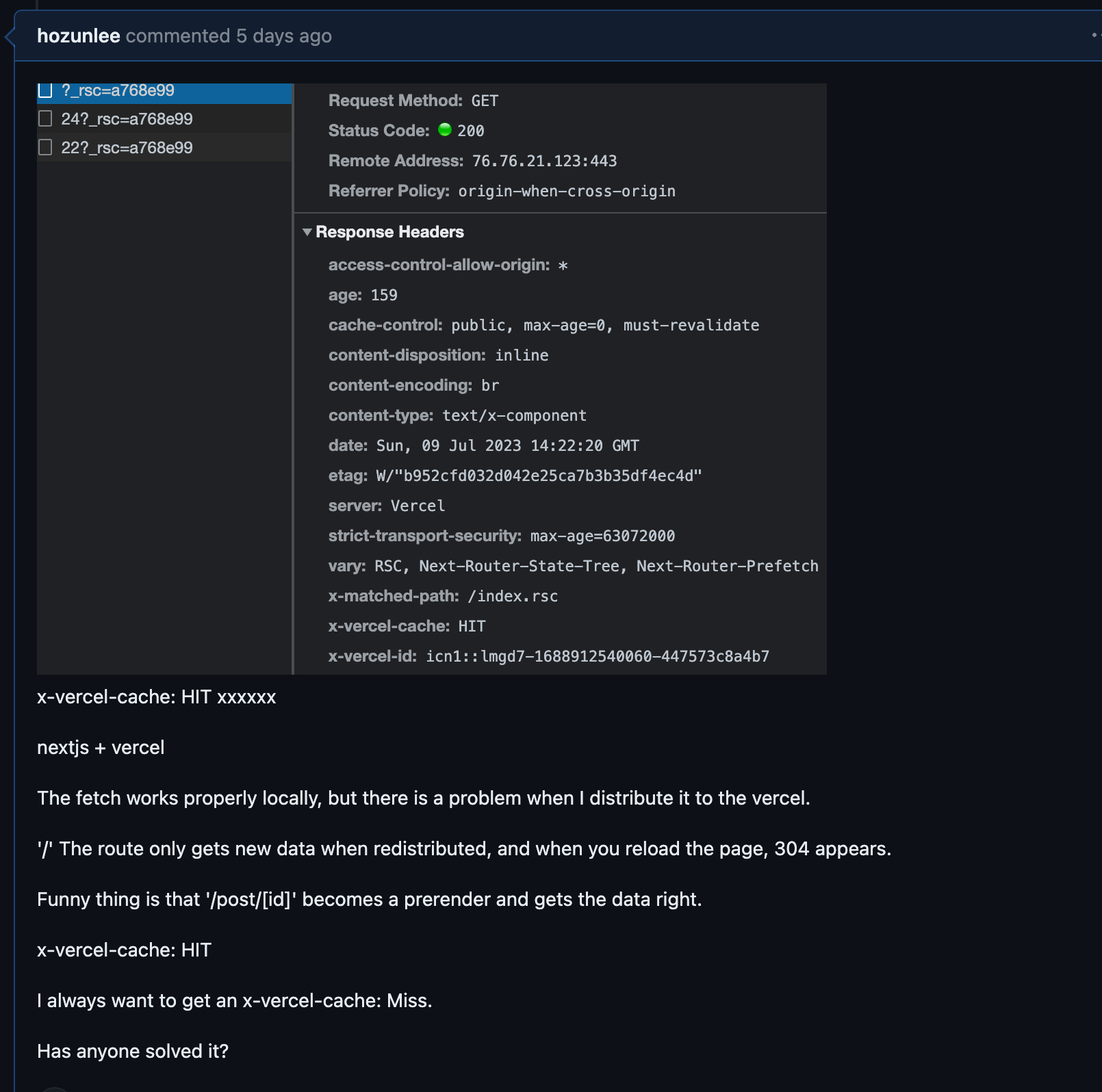
미친듯이 구글링했다. 3일밤낮을 Next13 caching fetched data even with the 'revalidate = 0' route segment
이런 글을 발견했다. revalidate 가 0 인데도 패치된 데이터가 캐시되는 나와 같은 사람이 등장했다. 그것도 3주 전.
Describe the Bug Next13 seems to be caching the data coming from supabase even with the revalidate = 0 route segment.
나와 같은 스택이다.
im having the same issue. I tried all of these
export const fetchCache = 'force-no-store'
export const revalidate = 0 // seconds
export const dynamic = 'force-dynamic'누가 솔루션이랍시고 제시한 이딴 방법들을 다 적용해보고 next.config 또한 죄다 모조리 No-store가 되도록 요청했지만 결론은 실패
지네디지단을 프로필로 설정해놓은 jandk008이란 친구는 버전을 낮추라한다. 역시 Next 의 문제일까. 질문을 올리고 기다려보기로 한다.
Got similar issue with nextjs + vercel and the fetched data is always cached no matter what solutions avoiding cache that is written in the document is used. But it works well locally. And the nextjs + vercel works well after I downgraded nextjs to 13.3.4 from 13.4.7. even with the sharing of reworked cache since 13.4.0 as someone else mentioned, it looks odd to have unfunctioning 13.4.0 versions. by, jandk008
아 그리고 Vecel의 문제일까봐 netlfy에다가도 배포해봤다.
음 역시나 캐싱이 된다.
strapi의 문제일까
이번엔 Strapi 커뮤니티에 방문했다. 징징거려봤다. 혹시 너희 문젠가 싶어서...
아무도 댓글을 안달아줬다.
역시나 next13의 문제?
넥스트 놈들이 캐싱을 잘해주는건 고맙지만 내가 원할 때만 해줘야지. header 값에 아무리 no-store, revalidate=0을 아무리 때려박아도 캐싱해주었다. x-vercel-cach:HIT!!!!!!!!!!!!!!!
아니 hit주지 말라고...
/posts/[id] 로 Fetch하는 값은 잘 불러와지는게 묘하다.
해결.
메인에서 불러오지 않고 컴포넌트를 통해 불러오거나, Post route를 초기에 리다이렉트 시키는 방식. 상상이상으로 많은 방법을 사용해보았지만, 모두 같은 현상이 발생했다.
nextjs 버전 다운그레이드를 준비하며, 침울해하고 있는 사이.
마지막으로 Route를 처음과 같이 /app/page.js 로 옮겨 패칭을 해봤다. 왠걸.
갑자기 잘 된다.
말이 안되지만 세상엔 어이없는 일들이 많이 일어난다. vercel + nextjs 팀이 밤새도록 열심히 작업했다고 생각하겠다.
https://bloggyu.com
다음은 지금까지 만든 기본 기술로 나의 블로그를 하나 만들어서 이 Velog를 이사갈 예정이다.
도메인 연결
구글 도메인을 하나 구매해서 vercel에 연결했다.
A와 CNAME을 연결해주면 된다. 진짜 10분도 안되서 도메인을 연결시킬 수 있다.
server (strapi) 또한 간결한 도메인을 주고 싶어서 sub domain을 하나 연결해 server.domain.com을 Koyep에 Cname을 연결해주었다.
😌 왜 워드프레스와 클라우드웨이즈보다 좋은가?
기본 전제는 당신이 개발자이거나 개발자의 동료가 있거나 개발자를 고용하거나
- 고정비가 대폭 줄었다. 실제로 나가는 유지비는 domain 비용 1년에 12불 정도이다. 서버비 호스팅비 다 필요없다. 용량 제한은 있지만, 아껴쓰거나 트래픽이 늘어났을 때 추가적인 비용집행 판단을 내릴 수 있다.
- 개발자의 입장에서는 괜찮은 포트폴리오가 된다. 내가 풀스택을 어쨌든 씹어먹어본 입장이니, A-Z 나만의 서비스를 만들었다.
- 콘텐츠 크리에이터 입장에서는 꽤 괜찮은 대쉬보드를 제공한다. 뭐 지금 사용하는 기능이야 기껏해야 마크다운으로 글을 작성하고 임시저장 하는 정도지만, 엔티티를 더 세밀하게 짜놓으면 카테고리 관리 등 자기의 글을 효율적으로 관리할 수 있다.
- 자유도가 높다. 사실 초기에 구현하기 어려운 단점은 있지만, 한 번 구현만 해놓으면 무한 확장과 스타일적용이 가능하다.
결론
next 13은 그냥 쓰지말고 제대로 써야된다. 진짜 짜증이 많이 났는데, 공식문서는 친절히 정답을 알려주고 있었다.
어디가 문제인지를 발견하는 과정이 제일 어려웠다. 하나의 프레임워크라면 에러를 찾아내기가 쉽다.
풀스택을 다루다보니 어디가 문제인지 찾기가 매우 힘들었다. 자세히 봐야하는데 빨리 처리하려다 보니 놓치는 부분에서 결국 문제가 발생했다.
하지만 충분히 재미있었다.
상상으로만 준비했던 기술 스택이 맞물려 조화롭게 작동했다.
심플하게 쌓아 심플한 현실을 그리자는 하루키처럼. 조금 더 심플한 코드를 짜고 심플한 웹을 그리고 싶다.
그럼 이만.
update. 23.07.18 무조건 캐싱 되는 문제때문에 초기 페이지 렌더링이 과하게 걸린다. 하나하나 지워보았는데,
//캐싱만될때
// export const fetchCache = "force-no-store";
export const revalidate = 0; // seconds
// export const dynamic = "force-dynamic";패칭하는 곳에서 이 것을 다시 주석해줬더니 무제한 패칭이 다시 일어났다.
이번 솔루션을 계기로 next13의 문제라는 것을 확실히 깨달을 수 있었다.
강제로 revalidate를 일으켜 캐싱을 없애는 것이다.
당연히 최적화와는 거리가 멀다. 초기 렌더링 속도가 느려서 vercel 분석에서 거의 최하점 받는 중
다음 블로그를 만들 땐 svelteKIT으로 만들 거다. 그리고 비교해봐야지