네이버 블로그 크롤링 솔루션에 Gemini CLI 를 연결한 이유 with python
_1751875418362.png)
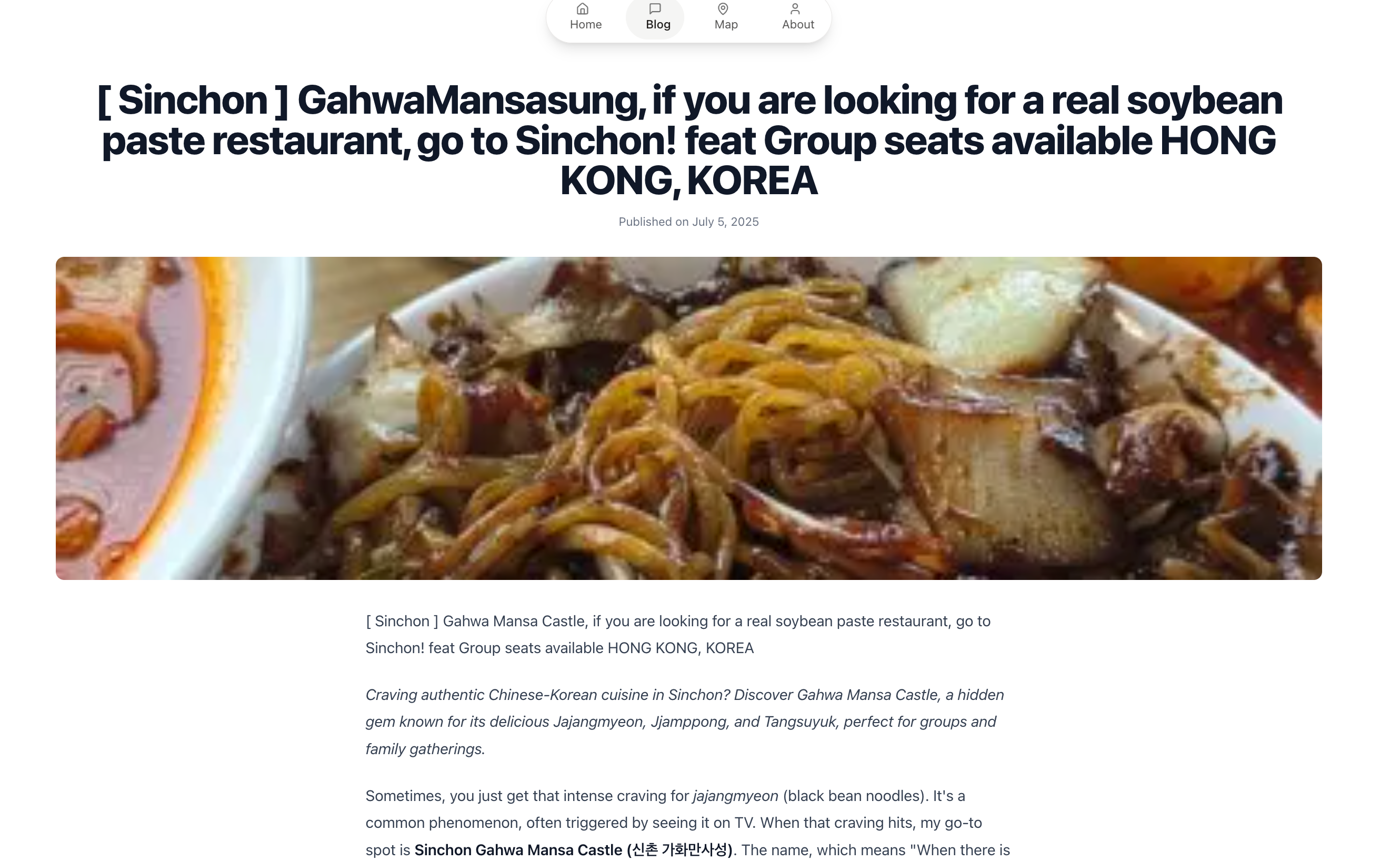
네이버 블로그 자동 크롤러 & 번역/DB 업로드 파이프라인 개발기 | python를 작성했었다. 그냥저냥 쓸만한 솔루션이었다. 근데 막상 프론트엔드 페이지를 만들고 배포해보니 조악하고 비루한 영어로 된 컨텐츠가 나왔다. 컨텐츠의 품질을 끌어올려야겠다고 생각했다. Gemini cli를 이용하고자 한다.
사이드 프로젝트로 시작했던 'AI 기반 콘텐츠 자동화 시스템'이 어떻게 진화했는지, 그리고 이 과정에서 얻은 기술적 경험을 공유한다. 반복적인 콘텐츠 번역과 최적화, 그리고 데이터 베이스 업로드 작업을 90%이상 자동화 하며 겪었던 고민과 해결 과정을 담았다.
- 번역 : 번역기를 돌리고 어색한 문장을 다듬는 데 시간 소모
- 최적화 : SEO 키워드를 넣고, 가독성을 높이기 위해 글을 재구성
- 업로드 : 이미지 다운로드 후 마크다운에 경로를 맞추고, 메타데이터와 함께 DB 삽입
=> 자동화 필요성
전체 기술 흐름(아키텍처) - Gemini 연동형 콘텐츠 발행 파이프라인 v2.2
[Naver Blog RSS] → [크롤링/파싱] → [DeepL 번역] → [마크다운/메타 저장 (eng/)] →
[AI (Gemini) 기반 콘텐츠 개선 및 메타데이터 최적화 (upload/)] →
[사용자 검토 및 승인] → [Supabase 업로드] → [파일 아카이빙 (eng_done/, upload_done/)]Gemini CLI
구글이 2025년 6월 공개한 제미나이 CLI는 터미널 환경에서 작동하는 AI 코딩 도구로, 개발자가 자연어 명령으로 다음 작업을 수행할 수 있습니다:
코드 생성/분석: 웹사이트 제작 요청 시 소스코드 복제·분석 후 자동 생성. 실시간 컨텍스트: 구글 검색 연동으로 웹 페이지를 가져와 프롬프트 정확도 향상. 배포 자동화: 생성 결과를 구글 클라우드 런 통해 전역 배포1. 메모리 관리: 작업 폴더 자동 지정 및 MVC 분리·로그 시스템 구축 지원.
아키텍처 설계 : 모놀리식에서 3단계 파이프라인으로
초기 버전(이전 블로그 글)에서는 크롤링부터 DB 업로드까지 하나의 스크립트로 동작하는 모놀리식 구조를 설계했다. 하지만 중간에 오류가 발생하면 처음부터 다시 시작해야했고, 블로그 글을 AI로 개선하고 싶어도 개선할 수없는 문제가 있었다.
Gemini-Integrated Content Publishing Pipeline
각 단계는 독립적으로 실행되며 파일 시스템을 통해 데이터를 주고 받는다. 이 구조는 유연성과 안정성을 높여주었고, 컨텐츠의 퀄리티를 높여줬다.
개선된 3단계 파이프라인
- 크롤링 - 번역 -> 2. Gemini cli를 활용한 post 개선 -> 3. supabase upload
[Naver RSS] → [크롤링/번역] → [eng/ 폴더] → [AI 콘텐츠 개선] → [upload/ 폴더] → [사용자 검토] → [Supabase 업로드] → [아카이빙]
Phase 1: 콘텐츠 수집 및 초기 번역 (eng/ 폴더 생성)
사용 api : rss DeepL api pplx api
첫 단계는 원재료를 수집하고 1차 가공하는 과정이다.
새 글 감지: feedparser로 네이버 블로그 RSS를 스캔해 새로운 포스트를 찾아낸다. 특정 카테고리를 select 할 수 있다.
크롤링 및 파싱: Selenium과 BeautifulSoup으로 본문, 이미지, 주소 등의 정보를 정교하게 추출. 그룹화된 이미지 섹션도 모두 추출하도록 설계했다.
초벌 번역: DeepL API를 사용해 추출된 텍스트를 영어로 번역한다. DeepL의 뛰어난 문맥 인식 능력 덕분에 꽤 자연스러운 초벌 번역본이 나온다.
주소 추출 및 여행지 추천 : 추출한 포스팅에서 주소를 추출하는 로직을 개발해 주소를 추출하고 해당 주소를 통해 pplx api (llm)를 통해 해당 주소 기반 여행지 3곳 테마를 추천한다.

파일 및 메타데이터 저장: 번역된 마크다운(.md) 파일과 별도로, 원본 URL, 주소, 태그 등의 정보를 담은 메타데이터(.meta.json) 파일을 eng/ 폴더에 생성한다. 콘텐츠와 메타데이터를 분리한 덕분에 데이터 관리가 훨씬 수월하다.
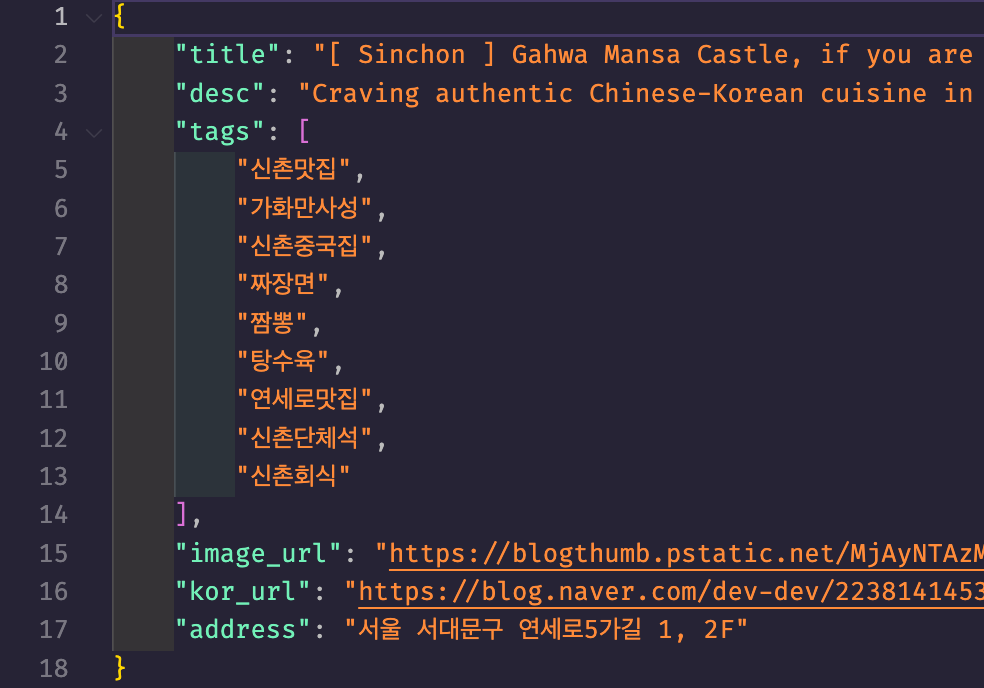
Phase 2: AI 에이전트의 콘텐츠 강화 (upload/ 폴더 생성)
이 단계가 파이프라인의 핵심. 이 과정을 단순히 API를 호출하는 것이 아니라, Gemini AI에게 작업을 위임하는 'AI 에이전트' 컨셉으로 설계했다.
CLI를 통해 AI 에이전트에게 지시를 내린다. "[Mapo Hongdae] Spicy Braised... .md" 블로그 글 개선해줘
그러면 AI 에이전트는 다음과 같은 작업을 수행합니다.
콘텐츠 재작성: eng/ 폴더의 원본 번역본을 읽어 본문만 재작성한다. SEO 키워드를 자연스럽게 녹여내고, 독자의 흥미를 끌 수 있는 스토리텔링을 가미하며, 원본의 사진을 모두 활용하도록 지시하여 콘텐츠의 양과 질을 동시에 높인다.
메타데이터 무결성 유지: 이 부분이 매우 중요하다. AI가 새로운 설명을 만들고 태그를 업데이트하더라도, title, image_url, kor_url 등 원본의 핵심 메타데이터는 절대 변경하지 않고 그대로 복사하도록 설계했다. 이를 통해 데이터의 정확성과 일관성을 보장했다.
결과물 저장 및 아카이빙: 강화된 콘텐츠(.md)와 업데이트된 메타데이터(.meta.json)를 upload/ 폴더에 저장합니다. 그리고 작업이 끝난 원본 파일들은 즉시 eng_done/ 폴더로 이동시켜 중복 작업을 방지합니다.
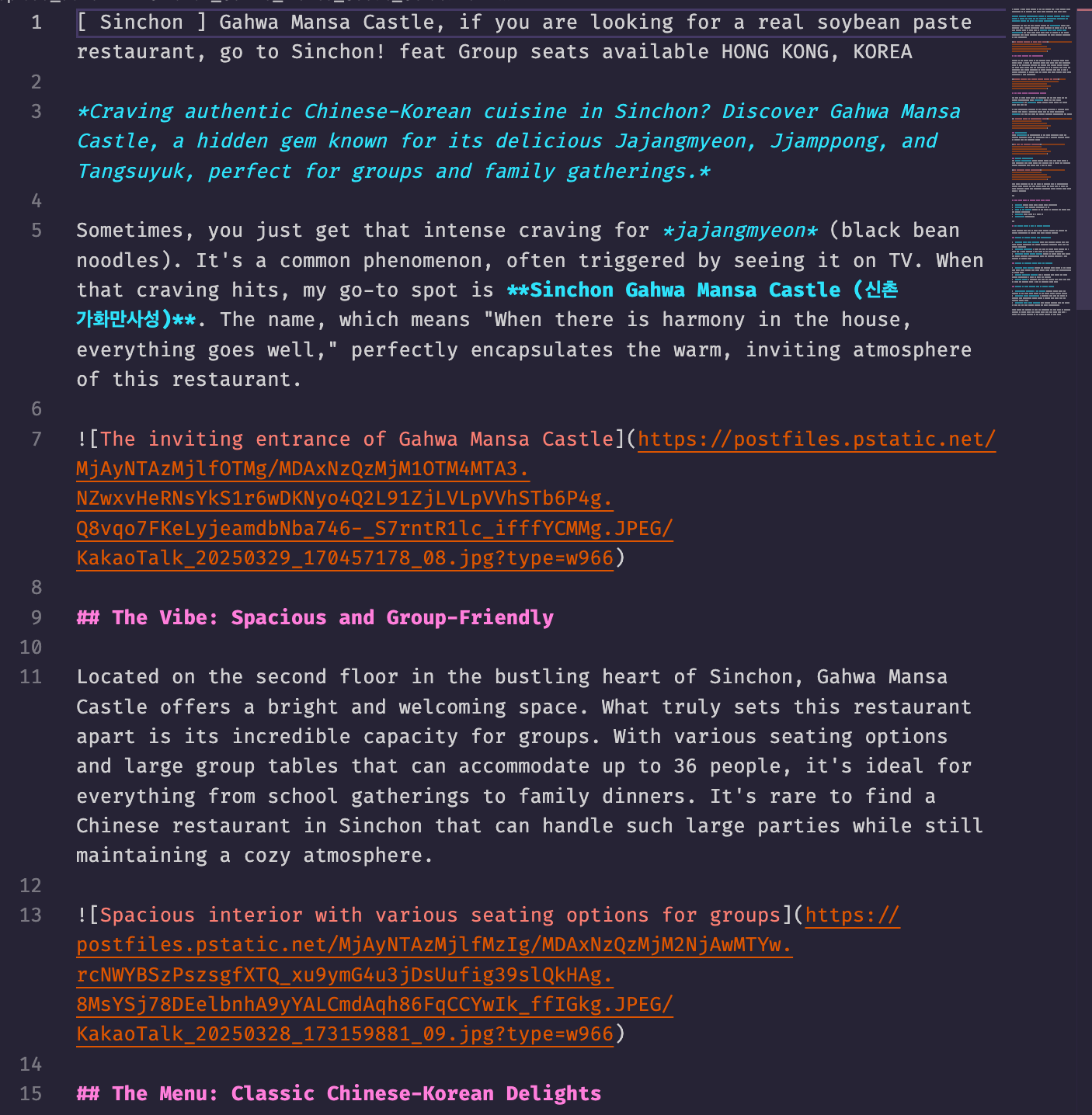
Phase 3: 최종 검토 및 발행 (upload_done/ 폴더로 이동)
최종 발행 전에는 사람의 검토 필요.
사용자 검토: upload/ 폴더에 생성된 최종 결과물을 제가 직접 확인.
발행 지시: 콘텐츠에 만족하면, 다시 AI 에이전트에게 업로드를 지시한다. "upload" 폴더를 순회해서 supabase 업로드 진행해줘
Supabase 업로드: components.uploader 모듈이 upload/ 폴더의 파일들을 읽어 Supabase 데이터베이스에 업로드.
최종 아카이빙: 업로드에 성공한 파일들은 upload_done/ 폴더로 이동하며 전체 워크플로우 마무리.
이 체계적인 폴더 구조 덕분에 각 단계의 진행 상황을 명확히 파악하고, 문제가 발생했을 때 추적하기가 매우 용이.
.
├── eng/ # (처리 대기) 초기 번역 파일
├── eng_done/ # (개선 완료) 원본 아카이브
├── upload/ # (업로드 대기) AI 개선 완료 파일
└── upload_done/ # (발행 완료) 최종 아카이브
결론
사실 전체 자동화 할 수 있었다. 하지만 api를 사용하기엔 token으 부담이 있었다. 모든 블로그글을 개선하기엔 token이 많이 든다. 그래서 3단계 파이프라인으로 구분하여 google cli를 사용하여 블로그 글을 SEO 최적화 되도록 설계했다. 개인의 상황에 맞는 개발전략은 필수적이다. 이렇게 아키텍쳐를 개선하면서 블로그 글을 사용자의 입장에서 검토할 수 있었다. 이는 자율 주행의 단계와 비슷하다고 본다. 아직은 사람의 역할이 필요하다.
다음은 프론트엔드 tasty 4 seoul 기획과 구현으로 찾아뵙겠다.