Nextjs 백엔드 대신 만들어드립니다. Feat Supabase : 데이터 기반 장기렌트 견적 추적 서비스 (1)

백엔드 공간만 만들어줍니다. 활용 구상은 니들이하세요. 🥳Say supabase
나는 여전히 프론트엔드 개발자이다. 그래서 풀스택 서비스를 개발하기 위해 여러가지 제약이 있었다. 지금까지 배운 것과 견줄 수 있는 방대한 백엔드와 서버에 대한 공부를 해야했다. 하지만 어디서부터 어디까지 해야할지 감조차 오지않았고, 일단 서비스를 만들고 싶기때문에 쉬운 방법을 찾고 선택했다.
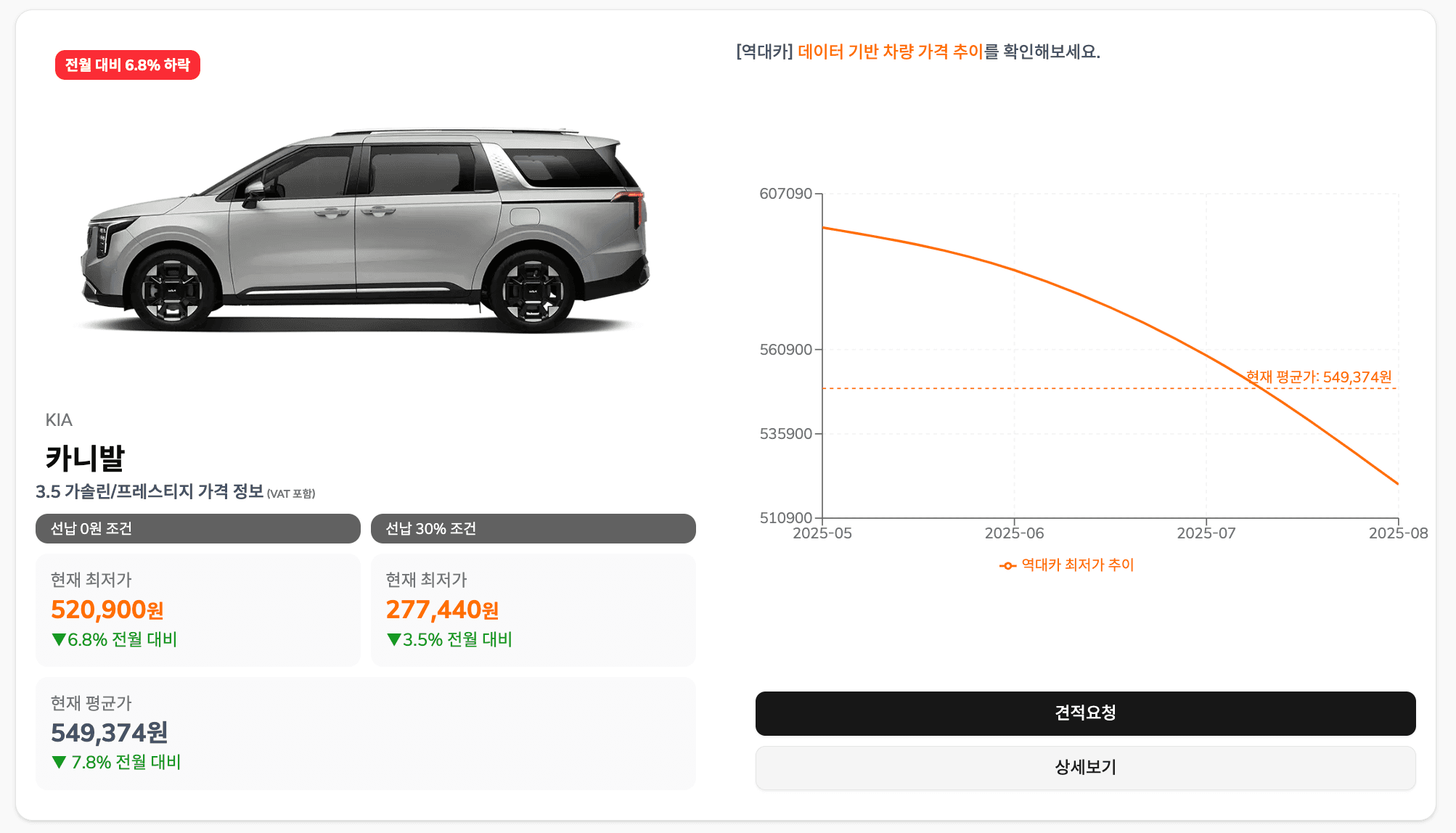
'역대카' 프로젝트는 흩어져 있는 신차 장기렌트 가격 정보를 데이터 기반으로 분석하여, 사용자에게 최적의 계약 타이밍을 알려주는 서비스입니다. https://alltime-car.com
아키텍처 철학 : 왜 next.js, Prisma 그리고 Supabase를 선택했나...요?
프로젝트를 시작하며 가장 중요하게 생각한 것은 '빠른 실행'과 'MVP 확보'였다. 이를 위해 기술적 결정을 내렸다. 특히 백엔드를 따로 배포하지 않아도 된다는 점이 맘에 들었다.
풀스택 프레임워크로서의 Next.js
과거에는 프론트엔드(React)와 백엔드 (node.js/Express)를 분리하여 개발하는 것이 일반적이었고, 나도 그렇게 개발해왔다. 그래서 데이터를 받아 그려만 주는 프론트엔드 작업을 충분히 해냈다. 하지만 이는 두 프로젝트 간의 API 명세 동기화, CORS 문제, 중복되는 타입 정의 등 추가적인 관리 포인트를 만들어내고, 1인 개발자에겐 여러가지 불편한 제약들을 만들어내곤 했다.
그러다 next.js, svelteKit 같은 풀스택 프레임워크들이 발전하기 시작했다. 특히 이번 프로젝트에선 Nextjs를 사용하여 트렌드와 많은 정보량에 도움을 받기로 했다. App Router 기반 Next.js 15 version은 Express 서버를 대체할 수 있다. 이유
서버액션(Server Actions)과 API 라우트 핸들러를 통해 프론트엔드와 백엔드가 하나의 프로젝트 안에서 유기적으로 동작합니다.
- API 구현 내장 : App Router의 Route Handlers로 REST 엔드포인트를 파일 기반 라우팅으로 구현하고 외부 클라이언트에서도 호출 가능해 "백엔드 서버 역할"을 수행한다. 표준 HTTP 메서드, 스트림, 다양한 응답 형태를 지원한다.
- 서버 로직 소환 : Server Actions는 컴포넌트에서 서버 함수를 직접 호출해 폼/뮤테이션 흐름을 단순화하여 전형적 보일러플레이트를 예방함. (POST 기반) 내부 상태 변경과 UX 단순화에 유리함.
프론트엔드 개발자가 풀스택으로 확장하는 방법론
Next.js는 React 개발자에게 백엔드 개발의 진입 장벽을 낮춰준다. 복잡한 Express 서버 설정 없이, 배포 없이, API 엔드포인트 없이, async 함수를 정의하는 것만으로 서버 로직(Server Action)을 만들 수 있다. 마치 프론트엔드에서 비동기 함수를 호출하듯 데이터베이스를 조작할 수 있다는 점은, 나와 같은 프론트엔드 배경을 가진 개발자가 풀스택 역량을 갖추는 데 큰 도움이 되었다. 결국 프론트엔드를 잘하려면 프로젝트 전반을 이해해야 하는 맥락과 같다.
Backend 대신 만들어드립니다. supabase and Prisma
프로젝트 초기, 가장 빠르게 프로토아입을 만들고 핵심 기능( EV3 특가 보여주기)에 집중하기 위해 BaaS(Banckend as a Service)인 Supabase를 선택했다. 그리고 Prisma를 선택했다.
Next.js + Supabase(PostreSQL) + Prisma 서버리스 환경에서 보안·인증·실시간·스키마 DX를 한 번에 갖추고 관리형 PostreSQL 데이터베이스와 간편한 소셜 인증 기능을 제공하여 인프라 구축 시간을 획기적으로 줄일 수 았다.
하지만 데이터베이스와 직접 상호작용하는 레이어는 Prisma ORM
supabase는 자체적으로 supabase-js 클라이언트를 제공하여 DB에 접근할 수 있게 한다. 하지만 우리는 ORM사용하려고 한다. 이유
- 타입 안정성 (Type Safety): supabase-js는 쿼리 결과를 any나 제네릭 타입으로 반환하는 경우가 많아, 컴파일 시점에 데이터의 타입을 완벽하게 보장하기 어렵다. 반면 Prisma는 schema.prisma 파일을 기반으로 완벽하게 타입이 지정된 클라이언트를 자동 생성한다. 이를 통해 Car 모델을 조회하면 Car 타입이 반환되는 것을 보장받을 수 있어, 코드의 안정성과 예측 가능성을 극대화할 수 있디.
- 직관적인 관계 쿼리 (Intuitive Relation Queries): 복잡한 JOIN 쿼리를 작성해야 할 때, Prisma의 include나 select 옵션은 SQL을 직접 작성하는 것보다 훨씬 직관적이고 생산성이 높다. 예를 들어, 특정 차량의 모든 엔진과 각 엔진의 모든 트림을 한 번에 가져오는 쿼리는 다음과 같이 간단하게 표현된다.
1 const carWithEnginesAndTrims = await prisma.car.findUnique({
2 where: { id: 1 },
3 include: {
4 CarEngine: {
5 include: {
6 carTrims: true,
7 },
8 },
9 },
10 });
- 마이그레이션 관리 ( db 형상관리) : git을 사용하는 이유랑 비슷하다.
prisma migrate명령어를 통해 데이터베이스 스키마 변경 이력을 체계적으로 관리할 수 있게 된다.
결론적으로, 인프라의 편리함은 Supabase 에서 얻고, 앱의 코드 안정성과 생산성은 prisma를 통해 확보한다. 풀스택 백엔드가 확보된 것이다. 나는 주로 프론트엔드 개발을 해나가기 위해 CMS나 firebase / supabase를 사용했는데, 매우 효율적이라고 느꼈다. 여러가지 설정과 배포에서 해방된다. 이는 빠른 개발에 큰 도움을 준다. (경험담)
데이터 모델링 : 서비스의 뼈대를 만들자
과거 팀프로젝트를 할 땐 데이터와 백엔드 개발자들이 API 쓰세요. 하고 주면 쓰면 됐다. 냉혹한 현실은 그게 통용되지 않는다. 내가 요즘 개발할 때 가장 많이 하는 생각은 이 것이다.
Data first!
어떤 데이터를 활용하고 어떻게 front 단에 전달할지에 대한 고민이 엄청나게 필요하다. 모든 사업의 뼈대와 개발의 핵심은 결국 백엔드 서비스라고 프론트엔드 개발자인 나는 생각하게 되었다. 그래서 개발 순서 흐름대로 정해지게 되었다.
아키텍처 설계 -> 스택 선정 -> ERD (어떻게 모을 것인가) -> API (무엇을 보여줄 것인가) -> | front( 어떻게 보여줄 것인가)
이런 빙산이 숨어있다. 그래서 ERD를 그리는데 총력을 다했다. 작은 아이디어에서 확장해나간다. 목적 : 장기렌트 차량 견적을 모으자. 데이터를 쌓아서 그래프로 보여주자. 차량 데이터를 활용해보자. 지나고 생각해본 거지만, 정말 재밌는 작업이었다.
왜 그래야하는지 타입으로 정의되고 도태되고 살아남는 과정이 스키마를 통해 그려진다.
마치 다윈의 진화론 같다.
ERD는 차량에 비유를 많이 한다.
그 도메인 서비스의 구조를 한 눈에 볼 수 있기 때문이다. 결국 기획의 영역이다.
핵심 모델 관계 : car - engine - trim - estiamte
- Car → CarEngine (1:N) : 하나의 차량은 여러 엔진 타입을 가질 수 있습니다.
- CarEngine → CarTrim (1:N) : 하나의 엔진은 여러 트림을 가질 수 있습니다.
- CarTrim → RentalEstimate (1:N) : 하나의 트림에 대해 여러 렌트사의 월별 견적이
존재합니다.
- CarTrim → MonthlyEstimateStat (1:N) : 월별 평균/최저 가격 통계를 저장하여 빠른
조회를 가능하게 합니다.나는 차가 없다. 그래서 차에 대해 잘 모른다. 공부를 했다. 해야했다. 현대차 내차 만들기에 들어갔다. 내가 아는 차가 보였고, 그 안에 엔진과 트림이라는 것이 보이기 시작했다. 아 가솔린, 아 디젤, 아 전기차. 그 안에 특정 옵션의 트림. 이제야 판매되는 차량에 대해 이해가 가기 시작했다. 1개의 차에도 수 가지의 옵션으로 인해 다른 차로 변모하게 되는 것이다. 생각해보면 아 그럼 1개의 차에도 여러가지 견적이 생길 수 있겠구나. 예를 들어 ev3에 1:1로 견적이 매칭되는게 아니고 ev3 - 전기엔진 - 스마트/밀레니엄/레전드 이렇게 3개의 트림에 견적이 1개씩 매칭되는 구조이다.
점점 복잡해짐을 느끼면서, 그래도 뭔가 깨달았다는 안도감을 느끼면서. 스키마를 설계해 나갔다.
1 // packages/database/prisma/schema.prisma (일부)
2
3 model Car {
4 id Int @id @default(autoincrement())
5 name String
6 carCode String @unique
7 CarEngine CarEngine[]
8 // ...
9 }
10
11 model CarEngine {
12 id Int @id @default(autoincrement())
13 car Car @relation(fields: [carId], references: [id],
onDelete: Cascade)
14 carId Int
15 carTrims CarTrim[]
16 // ...
17 }
18
19 model CarTrim {
20 id Int @id @default(autoincrement())
21 CarEngine CarEngine @relation(fields: [carEngineId],
references: [id], onDelete: Cascade)
22 carEngineId Int
23 RentalEstimate RentalEstimate[]
24 MonthlyEstimateStat MonthlyEstimateStat[]
25 // ...
26 }
27
28 model RentalEstimate {
29 id Int @id @default(autoincrement())
30 carTrim CarTrim @relation(fields: [carTrimId], references:
[id], onDelete: Cascade)
31 carTrimId Int
32 monthlyPrice Int
33 // ...
34 }
35
36 model MonthlyEstimateStat {
37 id Int @id @default(autoincrement())
38 carTrim CarTrim @relation(fields: [carTrimId], references:
[id], onDelete: Cascade)
39 carTrimId Int
40 averagePrice Float
41 lowestPrice Float
42 year Int
43 month Int
44 // ...
45 }
ERD가 도출되었다. 이러한 구조를 통해 차량의 기본정보부터 복잡한 가격 통계 데이터까지 일관성 있게 관리할 수 있게 되었다.
Auth
Supabase의 가장 큰 장점 중 하나는 간편한 인증이다. 카카오 소셜 로그인을 구현하고, 인증이 완료된 사용자를 서비스의 User 테이블과 동기화하는 로직을 auth/callback 라우트에 구현했다. 잠재 user를 만들고 user에게 가격 변동을 알리는 카카오톡 푸쉬를 넣으려고 구상했다.
1 // apps/service/src/app/auth/callback/route.ts (로직 요약)
2
3 export async function GET(request: Request) {
4 // ... Supabase에서 code를 session으로 교환
5 const { error } = await supabase.auth.exchangeCodeForSession(code);
6
7 if (!error) {
8 const { data: { user } } = await supabase.auth.getUser();
9
10 if (user) {
11 // 우리 DB에 유저가 없으면 새로 생성
12 const isExist = await prisma.user.findFirst({ where: { email:
user.email } });
13 if (isExist === null) {
14 await prisma.user.create({
15 data: {
16 name: user.user_metadata.name,
17 email: user.user_metadata.email,
18 authority: 'USER',
19 },
20 });
21 }
22 }
23 return NextResponse.redirect(origin);
24 }
25 // ...
26 }이 과정을 통해 Supabase가 인증을 처리하고, 저희 백엔드는 비즈니스 로직에 더 집중할 수 있었다.
데이터 확보는 어떻게 할건데... 크롤링!
엄청난 문제에 직면했다. 수만 가지에 달하는 차량, 엔진, 트림 정보를 수동으로 입력하는 것은 불가능에 가깝다. apps/admin 프로젝트의 핵심 기능은 사실 바로 데이터를 자동 수집하는 크롤러 기능을 내장했다.
- 전체 차량 데이터를 확보해야 한다.
- 렌터카 업체 리스트를 확보한다.
- 렌터카 업체별 차량의 견적을 확보한다.
- 다 내가 해야한다. ** 핵심 **
차량 전체 데이터를 확보 하는 방법
현대차와 기아차에서 가져오면 어떨까 생각했다. 그래서 현대와 기아를 들어가봤다. 차량이 일목요연하게 잘 정리되어 있어서 데이터만 잘 가져오면 정제해서 우리 데이터베이스에 넣을 수 있을 것 같았다. 현대는 api를 활용했고, 기아는 Playwright 로 E2E 를 활용했다.
이때도 마찬가지로 car를 완성하고, engine과 trim 을 차례대로 생성하고 관계시켜 생성한다.
이렇게 해서 수백대의 차량 엔진 트림 정보를 구축했다.
렌터카 업체리스트 확보
우리 영업팀과 연계되어 있는 장기렌터카 업체를 별도의 테이블에 구축한다. 18개 업체 이를 토대로 가격정보를 쌓아 나간다.
렌터카 업체별 차량 견적 확보
영업팀에서 2주 간격으로 차량별 견적을 업데이트 한다. 이를 토대로 특가 / 인기 / 가격하락 섹션의 아이템을 선정한다. 그리고 월별로 가격을 추적하는 테이블을 만들어서 가격 추이를 업데이트한다.
결론 : 그리고 내가 다한다.
활용에 따라 DB의 형태가 계속 변한다는 점이 인상깊었다. 계속 바뀌고 수정되며 DB가 점점 구축되어가고 있다고 느꼈다. 어차피 바뀌지만 초기의 형태를 잡아두는 건 정말 중요한 일이다. 결국 ERD 구조가 비즈니스의 구조가 되는 것이니 말이다. 바뀌고 수정되고 담아지고 지워지면서 서비스가 뼈대의 형상이 그려지기 시작했다.
이제 이 날 것을 데이터를 어떻게 정제하고 사용할 것인지 백엔드와 프론트엔드를 아우르는 nextjs 의 활용을 고민해보자.